|
|
|
|
Datenverarbeitung
|
|
Detektor-Triggersystem
|
|
Die Datenmengen die z.B. vom CMS-Detektor generiert werden,
sind vergleichbar mit der einer Digitalkamera von 70 Megapixeln, die
pro Sekunde 40 Millionen Bilder schiesst. Da diese Frequenz von bis
zu 40 Millionen Protonenstrahlkreuzungen pro Sekunde jedes
Datenverarbeitungssystem überfordern würde, wurden die 4 grossen
Detektoren mit sogenannten Triggern ausgestattet. Diese Trigger
sollen bereits kurz nach der Detektion eines Teilchens darüber
entscheiden, ob diese Daten gespeichert oder verworfen werden
sollen. Jeder der vier Detektoren besitzt dabei ein spezifisches
Triggersystem. Grundsätzlich funktionieren aber all diese
Systeme, nach dem gleichen Prinzip. Die einzelnen Triggerstufen sind
untereinander über eine komplizierte Analysen- und
Steuersoftware mit übrigen Detektorbestandteilen verbunden.
Sehr viele Detektorsignaturen sind bereits aus anderen
Beschleunigerexperimenten bekannt. Solche Standardsignaturen
würden wertvollen Speicherplatz einnehmen. Sie werden daher
durch das Trigger Hard- und Softwarenetzwerk frühzeitig erkannt
und herausgefiltert.
Das Triggersystem kann in drei Hauptstufen unterteilt werden. Das
folgende Beispiel beschreibt das Triggersystem von ATLAS:
Level-1-Trigger:
Die Level-1-Trigger bestehen aus Hardware-Prozessoren, welche die
Daten aus einer Proton-Proton Kollision, in einer ersten groben
Auflösung miteinander vergleicht. Werden diese
Detektionsmerkmale vom System erkannt, werden die Daten zur
nächsten Triggerstufe weitergeleitet. Von den 40 Millionen
Strahlkreuzungen pro Sekunde werden in der ersten Triggerstufe etwa
75.000 ausgewählt und weitergeleitet, der Rest wird verworfen.
Level-2-Trigger:
Die Level-2-Trigger bestehen aus programmierbaren Prozessoren, in
denen die Daten vom Level-1 Trigger mit einer verbesserten
Auflösung analysiert werden. Weniger als 1.000 Ereignisse pro
Sekunde passieren die Level-2-Bedingungen. Diese Daten erreichen
dann die dritte Filterstufe - den Ereignisfilter.
Ereignisfilter:
Der Ereignisfilter besteht aus einer grossen Farm von vernetzten
Prozessorkernen, in denen eine vollständige Rekonstruktion und
Analyse der Daten aus den Level-2-Triggern durchgeführt wird.
Erst wenn diese Daten die Anforderungen dieser Filterstufe
erfüllen, wird das Ereignis für spätere Datenanalysen
auf Speichermedien geschrieben. Von den ursprünglich 40
Millionen Strahlkreuzungen werden schlussendlich nur ca. 200 pro
Sekunde gespeichert und für das WLCG bereitgestellt.
Datenmenge pro Sekunde:
• ATLAS: 320 Megabyte / Sekunde
• CMS: 220 Megabyte / Sekunde
• ALICE: 100 Megabyte / Sekunde
• LHCb: 50 Megabyte / Sekunde |
|
|
|
|
   |
WLCG - Worldwide LHC Computing Grid |
|
Der LHC verfügt über insgesamt 150 Millionen Sensoren in
allen Experimenten. Jährlich wird damit eine Datenmenge von 15
Petabytes (15 Mio. Gigabytes) generiert. Nicht einmal die
grössten Supercomputer, die sonst zur Bewältigung von
Forschungsdaten zur Verfügung stehen, könnten diese Last
bewältigen. Und auch die Leistung der bekannten Grids - etwa
das Seti@home-Projekt, ist für das was das LHC-Computing-Grid
leisten muss, viel zu gering. Vielmehr werden schon bestehende
Grids (zum Beispiel das Cern Openlab) benötigt, sowie tausende Rechner und
weitere hunderte Netzwerke, Cluster genannt, welche freie
Rechnerleistung bereit stellen.
Um diesen Anforderungen gerecht zu werden, wurde das Worldwide LHC
Computing Grid (WLCG) konstruiert. Es hat die Aufgabe die enormen
Datenmengen zu speichern, zu verwalten und zu verarbeiten. Für
das WLCG stellen 170 Rechenzentren aus 34 Ländern, über
100.000 Prozessoren zur Verfügung. Die durchschnittliche
Datenübertragungsrate beträgt, innerhalb des Grids, 400
bis 600 Megabyte pro Sekunde. Das Netzwerk wird in den kommenden
Jahren noch erweitert und seine Leistung damit kontinuierlich
gesteigert werden. |
|
|
 |
| CERN Computerzentrum |
Quelle: CERN |
|
Aufbau des WLCG |
|
Das WLCG besteht aus mehreren Stufen, sog. TIER's (tier; engl.
für Ebene). Jede Ebene erfüllt dabei ganz bestimmte
Aufgaben.
TIER-0:
Die erste Ebene wird als TIER-0 bezeichnet. Hier werden die
Rohdaten welche nach dem Ereignisfilter der Detektoren übrig
geblieben sind, in den CERN Rechenzentren auf Band gespeichert. Die
Rechenleistung wird dort zur ersten Rekonstruktion der Daten
genutzt, die dann wieder auf Tape und Disk gespeichert werden.
Insgesamt stehen 5.5 Petabyte Festplattenspeicher, 17 Petabyte
Magnetbandspeicher und 6000 vernetzte CPU's zur Verfügung.
Anschliessend werden Kopien dieser Daten zu den TIER-1 Zentren
verteilt.
TIER-1:
Zurzeit existieren 10 TIER-1 Zentren in verschiedenen Ländern.
In Deutschland, Frankreich, Italien, Kanada, Niederlande,
Skandinavien, Spanien, Taiwan, UK und zweimal in den USA. Am CERN in
der Schweiz ist ebenfalls ein TIER-1-Zentrum angesiedelt. Die TIER-1
Zentren verarbeiten die Daten erneut unter Berücksichtigung
neuer Kalibrierungen und wählen weitere mögliche
interessante Ereignisse aus. Ausserdem übernehmen sie die
Archivierung der TIER-2 Zentren mit den erzeugten Monte Carlo
Ereignissen. Mit einem Petabyte Festplattenspeicher, 10 Petabyte
Magnetbandspeicher und 2000 CPU's speichern die TIER-1 Zentren, die
komplette Kopie der Rohdaten aus Tier-0, als Backup.
TIER-2:
Zurzeit bilden ca. 150 Universitäten und
Forschungseinrichtungen, in 38 Ländern das TIER-2 Netzwerk.
Hier werden die eigentlichen Berechnungen und Analysen
durchgeführt. Die TIER-2 Zentren übernehmen spezialisierte
Computing-Grid Aufgaben, wie Datenverteilung, Monte-Carlo-Simulationen ,
Kalibrierungsermittlung und die endgültige Selektion der Daten.
Untereinander sind die TIER-2 Zentren über spezielle
Wissenschaftsnetzwerke oder über das Internet verbunden. Im
TIER-2 findet keine langfristige Datenspeicherung statt. Alle
Ergebnisse der Berechungen von TIER-2 werden zum Speichern wieder an
die TIER-1 Zentren geschickt. ,
Kalibrierungsermittlung und die endgültige Selektion der Daten.
Untereinander sind die TIER-2 Zentren über spezielle
Wissenschaftsnetzwerke oder über das Internet verbunden. Im
TIER-2 findet keine langfristige Datenspeicherung statt. Alle
Ergebnisse der Berechungen von TIER-2 werden zum Speichern wieder an
die TIER-1 Zentren geschickt.
TIER-3 / 4:
TIER-3 und TIER-4 steht den den Wissenschaftlern als Arbeitsplatz
bzw. als Zugriff zum GRID zur Verfügung. Hier können die
Daten des Grid abgerufen und Rechenanfragen eingegeben werden. |
|
|
|
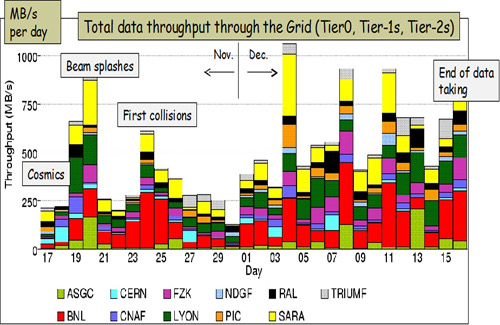 |
| Datenverteilung Tier 1+2 November/Dezember 2009 |
Quelle: LCG |
|
 |
| Beteiligte Rechenzentren |
Quelle: LCG |
|
Vorteile eines GRID's |
|
• Beim LHC-Projekt nehmen viele
Nationen teil. Diese Nationen wollen ihre finanziellen Resourcen
natürlich lieber auf lokalem Boden einsetzten, als für ein lokales
Rechenzentrum in der Schweiz.
• Ein Computer-Cluster aus normalen PC's ist gegenüber
eines Supercomputers wesentlich besser skalierbar. Es können
einzelne Teile hinzugefügt werden, ohne auf die teils starken
Einschränkungen eines Grosscomputers achten zu müssen. Mit
entsprechender Software (sog. Middleware) kann fast jede Art
Computer miteinander vernetzt werden.
• Wenn man sich nicht auf ein einzelnes, zentrales
Rechenzentrum verlassen muss, sondern viele kleine Rechenzentren zur
Verfügung stehen, dann ist auch die Ausfallsicherheit des
Gesamtsystems beträchtlich erhöht.
• Das Grid beruht, analog zum World Wide Web, auf offenen
Standards. Dadurch kann es sehr einfach erweitert werden und besitzt
ein hohes Mass an Flexibilität.
|
|
|
| |
|
|
|

